Line Plot¶
Draw a line plot with possibility of several semantic groupings.
plot: 'lineplot'
Plot-Specific Parameters
hue(str, list, numpy.ndarray, pandas.core.indexes.base.Index, or None, default: None)Grouping variable that will produce lines with different colors. Can be either categorical or numeric, although color mapping will behave differently in latter case.
size(str, list, numpy.ndarray, pandas.core.indexes.base.Index, or None, default: None)Grouping variable that will produce lines with different widths. Can be either categorical or numeric, although size mapping will behave differently in latter case.
style(str, list, numpy.ndarray, pandas.core.indexes.base.Index, or None, default: None)Grouping variable that will produce lines with different dashes and/or markers. Can have a numeric dtype but will always be treated as categorical.
units(str, list, numpy.ndarray, pandas.core.indexes.base.Index, or None, default: None)Grouping variable identifying sampling units. When used, a separate line will be drawn for each unit with appropriate semantics, but no legend entry will be added. Useful for showing distribution of experimental replicates when exact identities are not needed.
weights(str, list, numpy.ndarray, pandas.core.indexes.base.Index, or None, default: None)Data values or column used to compute weighted estimation. Note that use of weights currently limits the choice of statistics to a ‘mean’ estimator and ‘ci’ errorbar.
palette(str, list, matplotlib.colors.Colormap, or None, default: None)Method for choosing the colors to use when mapping the hue semantic. String values are passed to color_palette(). List values imply categorical mapping, while a colormap object implies numeric mapping.
hue_order(list or None, default: None)Specify the order of processing and plotting for categorical levels of the hue semantic.
hue_norm(tuple, matplotlib.colors.Normalize, or None, default: None)Either a pair of values that set the normalization range in data units or an object that will map from data units into a 0 until 1 interval. Usage implies numeric mapping.
sizes(list, tuple, or None, default: None)An object that determines how sizes are chosen when size is used. It can always be a list of size values. When size is numeric, it can also be a tuple specifying the minimum and maximum size to use such that other values are normalized within this range.
size_order(list or None, default: None)Specified order for appearance of the size variable levels, otherwise they are determined from the data. Not relevant when the size variable is numeric.
size_norm(tuple, Normalize object, or None, default: None)Normalization in data units for scaling plot objects when the size variable is numeric.
dashes(bool or list, default: True)Object determining how to draw the lines for different levels of the style variable. Setting to True will use default dash codes, or you can pass a list of dash codes. Setting to False will use solid lines for all subsets. Dashes are specified as in matplotlib: a tuple of (segment, gap) lengths, or an empty string to draw a solid line.
markers(bool, list, or None, default: None)Object determining how to draw the markers for different levels of the style variable. Setting to True will use default markers or you can pass a list of markers. Setting to False will draw marker-less lines. Markers are specified as in matplotlib.
style_order(list or None, default: None)Specified order for appearance of the style variable levels otherwise they are determined from the data. Not relevant when the style variable is numeric.
estimator(name of pandas method or callable, default: ‘mean’)Method for aggregating across multiple observations of the y variable at the same x level. If None, all observations will be drawn.
errorbar(str, tuple, or callable, default: (‘ci’, 95))Name of errorbar method (either “ci”, “pi”, “se”, or “sd”), or a tuple with a method name and a level parameter, or a function that maps from a vector to a (min, max) interval, or None to hide errorbar.
n_boot(int, default: 1000)Number of bootstraps to use for computing the confidence interval.
seed(int, numpy.random.Generator, numpy.random.RandomState, or None, default: None)Seed or random number generator for reproducible bootstrapping.
orient(str, default: None)Dimension along which the data are sorted / aggregated. Equivalently, the “independent variable” of the resulting function.
sort(bool, default: True)If True, the data will be sorted by the x and y variables, otherwise lines will connect points in the order they appear in the dataset.
err_style(str, default: ‘band’)Whether to draw the confidence intervals with translucent error bands or discrete error bars.
err_kws(dict of keyword arguments or None, default: None)Additional parameters to control the aesthetics of the error bars. The kwargs are passed either to matplotlib.axes.Axes.fill_between() or matplotlib.axes.Axes.errorbar(), depending on err_style.
alpha(float or None, default: None)Proportional opacity of the points.
legend(str or bool, default: ‘auto’)How to draw the legend. If ‘brief’, numeric hue and size variables will be represented with a sample of evenly spaced values. If ‘full’, every group will get an entry in the legend. If ‘auto’, choose between brief or full representation based on number of levels. If False, no legend data is added and no legend is drawn.
zorder(int or None, default: None)Axes order. The default drawing order for axes is patches, lines, text for each plot order.
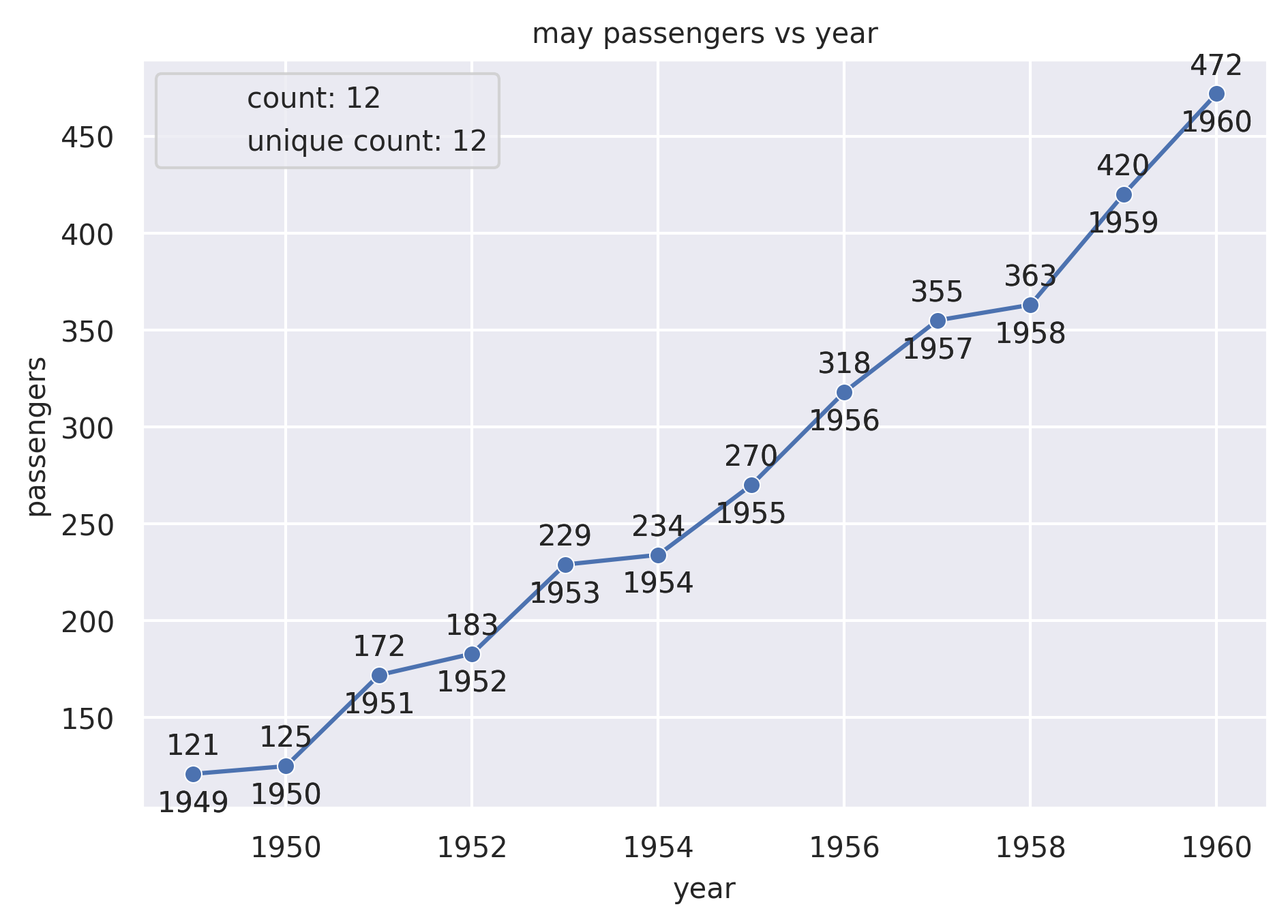
Example 1
from grplot import plot2d
import grplot_seaborn as gs
gs.set_theme(context='notebook', style='darkgrid', palette='deep')
flights = gs.load_dataset('flights')
may_flights = flights.query("month == 'May'")
ax = plot2d(plot='lineplot+scatterplot',
df=may_flights,
x='year',
y='passengers',
sep={'passengers': '.', 'year': None},
text=True,
ystatdesc='count+unique',
title='may passengers vs year')
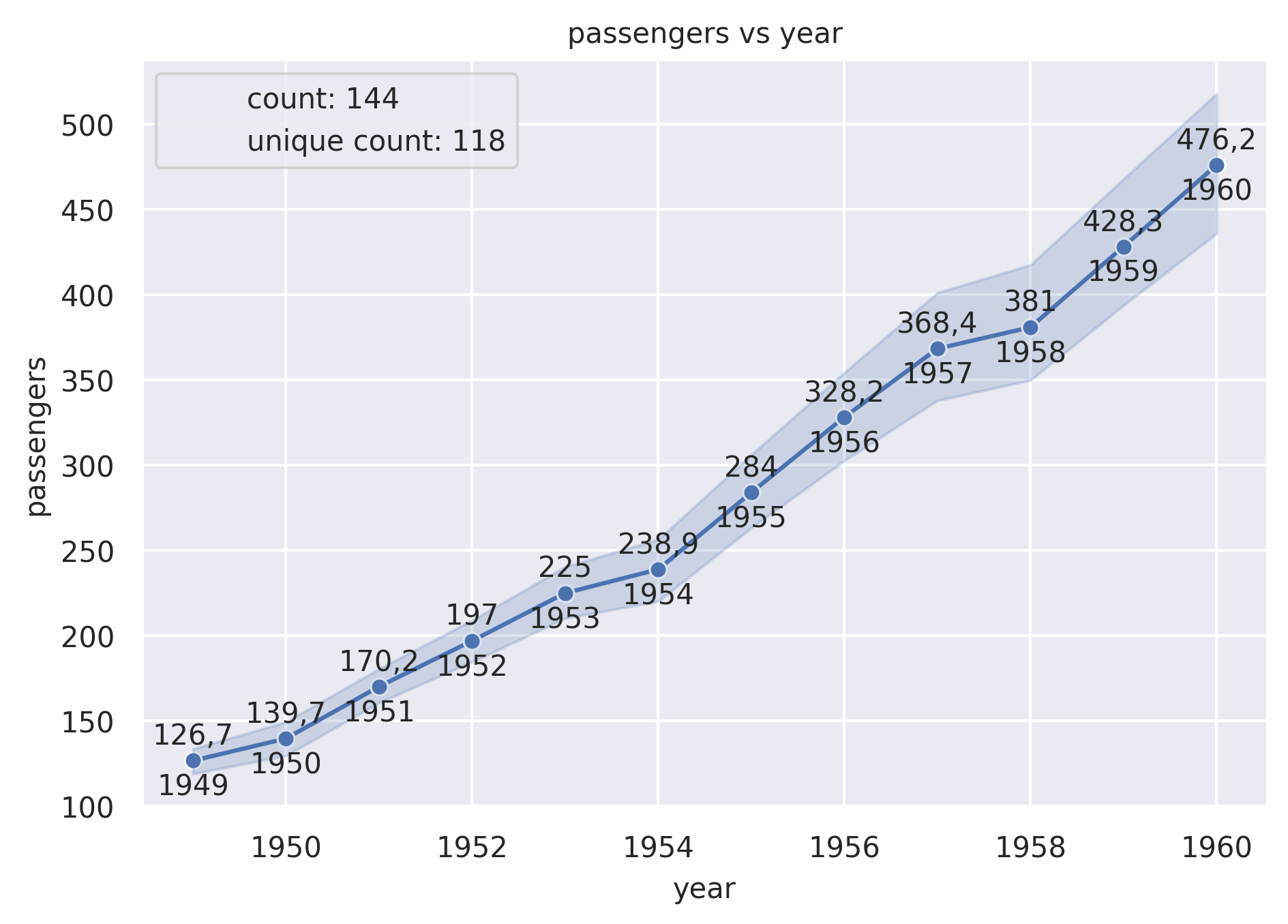
Example 2
from grplot import plot2d
import grplot_seaborn as gs
gs.set_theme(context='notebook', style='darkgrid', palette='deep')
flights = gs.load_dataset('flights')
ax = plot2d(plot='lineplot',
df=flights,
x='year',
y='passengers',
sep={'passengers':'.', 'year':None},
text=True,
ystatdesc='count+unique',
title='passengers vs year',
legend_loc='upper left',
errorbar=('ci', 95),
marker='o')